Overview
Overview of the approaches, issues in data, benchmarks, and deployment. Data issues are further divided into data scale, data distribution, and finetuning methods.
The current landscape
The landscape of physical AI foundation models has shifted rapidly from modular systems separating perception and control toward unified, multi-modal architectures that learn directly from large-scale data. The current frontier can be categorized into four main paradigms:
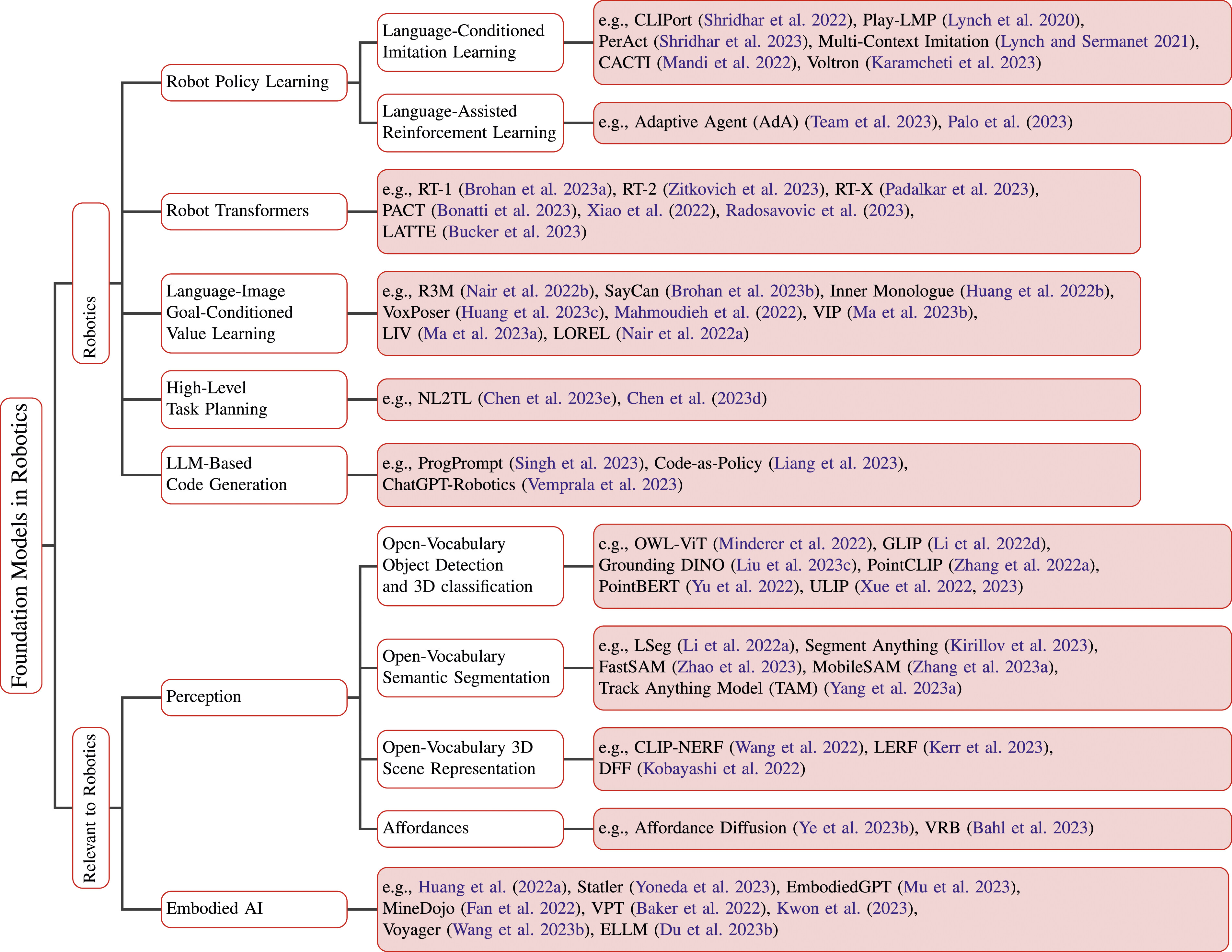
Vision-Language-Action (VLA) Models
End-to-end models that map directly from observations (vision) and instructions (language) to low-level robot control (actions), often fine-tuned from powerful web-scale Vision-Language Models (VLMs). Examples include RT-2, Octo, OpenVLA, Pi0, Project GR00T (which sets the standard for generalist humanoid control), and Lingbot (pushing the boundaries of language-driven manipulation).
World Models & World-Action Models (WAM)
Models that learn the dynamic transitions of the environment — predicting future states, generating video as a proxy for policy learning, or emitting world and action jointly. The family splits three ways: classical world models (Dreamer-style latent dynamics, trained in imagination); world foundation models (large generative video simulators like GeniE and Cosmos); and world-action models (WAM), which decode control tokens from the same latent stream that predicts video. DreamZero represents the cutting edge of the WAM line.
Large Vision-Language Models (VLMs) for Reasoning
Using off-the-shelf, frontier VLMs (e.g., GPT-4o, Claude 3.5) as high-level reasoners. Instead of direct motor control, they perform spatial analysis, goal-scoring, and step-by-step task planning or code generation, orchestrating lower-level skills. Examples include VLM-grounded planning, Code-as-Policy, and Eureka.
Data Scaling & Co-training Architectures
Efforts focused heavily on standardizing and scaling diverse embodied data. These architectures heavily leverage cross-embodiment co-training on massive multi-robot datasets to derive generalized policies. EgoScale and massive egocentric dataset priors are defining the new standard, alongside Open X-Embodiment efforts (RT-X) and DROID.
How this maps to the explorer: these four narrative buckets correspond to the explorer’s finer type taxonomy. VLA stays VLA — with Robot-Transformer (RT-1, Gato) split out as its pre-VLM precursor; VLMs-for-reasoning maps to LLM-planner; and data-scaling to the LBM scale bets plus from-scratch policies. The single world-models bucket above fans out into three explorer types: World-Model (Dreamer-style dynamics), World-FM (generative video simulators), and WAM (joint world-action models).
Data distributions
Data distributions skew wildly in the data sets that I have seen for any of these papers. A lot of them claim generalizability but a single task like pick and place tends to dominate the data set. As a result, the outcome—and the downstream evaluations these models hill-climb on—are deeply skewed by the implicit priorities of their datasets. I.e. What we have is things being good at pick and place or laundry folding not because this in any way proves the generalizability of the underlying models but it's because these are the tasks that we have data for.
As highlighted in recent literature (e.g., Foundation Models in Robotics), this essentially proves that Vision-Language-Action models (VLAs) are largely memorizing tasks rather than truly generalizing. However, in practical deployments, if the memorized distribution thoroughly covers the tasks you care about, then this might be okay.
- Embodiment coverage: Are we evaluating genuine cross-embodiment generalization, or just memorization of the tasks in the pretraining mix?
- Task entropy: Does the model actually support open-ended reasoning, or is it heavily biased toward the top 5% most frequent tasks (e.g. pick-and-place)? I actually don't think this is too much of a concern given that we are relying on the reasoning of some of these really large LLM backbones but depending on how you ablate the model, this could become a concern.
- Contact-rich coverage: How does bias against hard-to-collect tactile and force-feedback data skew evaluations against insertion or wiping tasks? We don't even have a basis to measure any of this since there's such a huge gap in the datasets collected.
The real struggles
Rather than manufactured constraints, the genuine bottlenecks the field is currently fighting include:
Contact-rich manipulation
Force and tactile feedback are rarely captured in imitation data. As a result, current VLAs are essentially blind to contact dynamics, making insertion or wiping tasks incredibly difficult to learn reliably. Workarounds: To bypass the challenge of engineering RL reward functions for force-feedback, many rely strictly on imitation learning (like ACT or Diffusion Policy).
Long-horizon tasks
As tasks stretch over longer time horizons, credit assignment degrades and the Supervised Fine-Tuning (SFT) ceiling becomes a hard wall. Reinforcement Learning (RL) fine-tuning is required to break past this, but remains notoriously expensive and unstable for flow-based models. Workarounds: The frontier is shifting toward hierarchical control (e.g., AsyncVLA, Steerable VLA) where a slow, high-level VLM handles the reasoning, while a fast, low-level policy handles the immediate execution. Others are pushing for flow-based RL fine-tuning (like πRL) to break the imitation learning ceiling directly.
Real-time edge inference
Flow-based continuous action models require iterative denoising steps, which introduces significant latency. While methods like FASTER provide some speedups, running these models in real-time on edge hardware (like a Jetson Orin) remains an unsolved bottleneck. Workarounds: Common strategies include distilling massive models down into edge-friendly variants (like SmolVLA or EdgeVLA) to preserve pre-trained priors while maintaining inference speeds, or using asynchronous architectures that decouple the reasoning loop from the local, high-frequency motor control loop.
Sim-to-real gap
Sim augmentation depends entirely on having a validated digital twin. Discrepancies in mass, friction, and control latency mean that simulated data often fails to transfer zero-shot to physical deployment. Workarounds: Instead of relying on perfect digital twins for zero-shot transfer, a common workaround is using simulation as a data multiplier (e.g., MimicGen): collecting a handful of real-world demonstrations (e.g., 15 teleoperated trajectories) and replaying them in MuJoCo with spatial perturbations to expand the dataset by 10× and force policies to learn robust recovery behaviors. I wonder though if the better solution here isn't to come up with a more sample-efficient way to achieve physical constraints for the exploration space.
Generalization to novel objects
Despite claims of generalist capabilities, VLAs still heavily struggle with objects that are outside of theor pretraining distribution. Workarounds: Unlabeled video pretraining on internet data (e.g., V-JEPA 2, ViPRA, LAPA). By predicting latent representations or optical flow from thousands of hours of YouTube videos, models learn the structure of the physical world before being fine-tuned on scarce robot data.
Deployment criteria
The gap between benchmark success and the production bar is massive.
- Bounded failure: A deployed policy must fail safely.
- Calibrated uncertainty: The model must recognize when it is out of distribution and cleanly hand off control to a human.
- Latency tail: Failure to arrive at fully planned action sequences must fail gracefully.
- Update path: When a new failure mode appears, you need a deterministic way to patch the policy or model. This requires capturing out-of-distribution samples in the wild and systematically routing them back into your training or evaluation pipelines. Similar to the "data flywheel" espoused by Tesla, deployed fleets must capture post-deployment edge cases.
Open Questions/Notes
- Data Scalability: For a given task, how much data do you nee? Can you quantify this by task complexity, horizon length, etc. Need some intuition around this
- Path/sequence diversity: While recording trajectories for a pick place behavioural cloning task, do you try to keep the leader arm's path as consistent as possible across episodes? If you don't keep it consistent but record a ton more episodes, what are you learning?
References
- Project GR00T: GR00T N1: An Open Foundation Model for Generalist Humanoid Robots. NVIDIA (2025).
- DreamZero: World Action Models are Zero-shot Policies. NVIDIA (2026).
- EgoScale: EgoScale: scaling dexterous robotic manipulation using large-scale egocentric human data. NVIDIA, UC Berkeley, UMD (2026).
- LingBot: A Pragmatic VLA Foundation Model. Ant Group (2026).